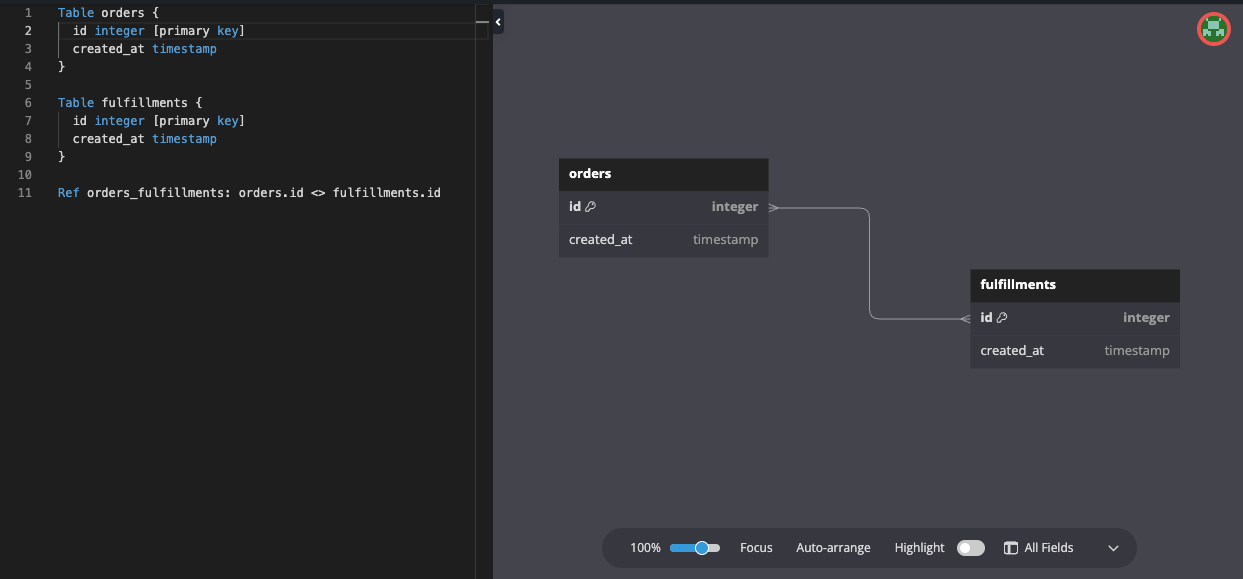
From this notation, what would you expect the generated SQL to look like?
If it takes only the primary keys for field names the SQL will not be valid - two fields will have the same name: id - so you would have to prepend the table name: books_id
But if people already use distinct primary key names, e.g. if the books table already has a primary key book_id, you would end up with the join table field called books_book_id.
And I think it will be equivalent to the following DBML:
Table books {
id int [pk]
name varchar
}
Table authors {
id [pk]
name varchar
}
Table books_authors {
id int [pk]
book_id int
author_id int
}
Ref: books.id > books_authors.book_id
Ref: authors.id > books_authors.author_id
But if people already use distinct primary key names, e.g. if the books table already has a primary key book_id , you would end up with the join table field called books_book_id .
Yes you’re right, though I guess if they really care about the structure of the bridge table, they can opt to go with the explicit (two many-to-ones) route.
The id primary key in this table is not necessary, the primary key needs to be a composite of the book_id and author_id, otherwise you have the possibility for duplicate rows.
Many ORM frameworks rely on a single PK per table but not all databases are designed for use with ORMs.